
My Attempt to Understand AI by Explaining It (With AI)
My best stab at simplifying core concepts

In my effort to understand more about artificial intelligence systems and how they are trained and work, I have been trying to create thorough, clear explanations of various concepts for myself through conversations with ChatGPT.
The following definitions are excerpts from those conversations, where I helped ChatGPT to come up with helpful metaphors or framing for the ideas, then utilized specific wording that ChatGPT used for these final explanations. I hope they prove useful to you. I may attempt to add more if I find a need for better understanding of other AI-related concepts. Here is a link to my ongoing conversation with ChatGPT that resulted in these explanations, so you can get a sense of how much of this work is “mine”.
I also welcome corrections or clarifications in the comments if you feel something is off here.
I recommend going in the order I have outlined below, as I think the concepts stack helpfully in this order, and I also build on metaphors and comparisons as I go.
Feature Vectors
I think of feature vectors as the “language” or “vocabulary” of AI programs. Everything you want to communicate with these programs gets “translated” into and out of these vectors.
In reality, feature vectors are numerical representations, or perhaps “GPS coordinates” that “map” the "trajectory" or "position" of an idea, voice, image, video, etc. Think of this map as existing in a space that could be visualized as three-dimensional (think of it as dimensions like height, depth, and width, though it can have any number of “dimensions”, depending on the complexity of the data). Each element (or dimension) of the vector corresponds to a specific feature or characteristic of the data. For instance, in text analysis, dimensions might include sentiment intensity, grammatical role, or semantic/contextual relationships. For images, dimensions could represent color values, edge detection, or texture patterns.
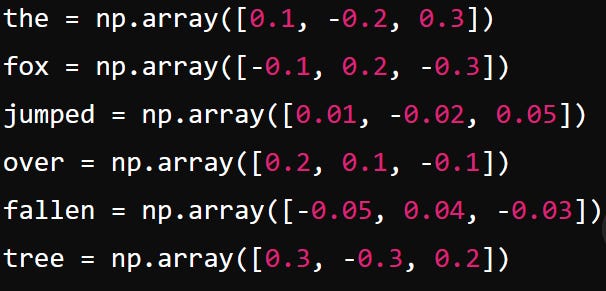
Pictured above is an example of a very simple feature vector code (the numbers in pink), translating the English text “the fox jumped over the fallen tree” into the AI’s native “language” or “idea coordinates”.
The length of the vector (i.e., the number of dimensions or elements it contains) determines the level of detail and complexity the vector can encapsulate about the data. While more dimensions allow for a richer representation, they also can increase the risk of "overfitting," where a model might perform well on training data but poorly on unseen data because it has learned to capture noise and exceptions too finely (too many dimensions and not enough data to reliably generalize those dimensions upon). In other words, there’s a “sweet spot” of complexity in these models.
The design of feature vectors is also important. This is akin to crafting the vocabulary that AI uses (the amount, type, complexity, and variation of “words” in its “language”) to interpret and interact with the world. Just as the richness of an author's vocabulary can enhance the clarity and expressiveness of their writing, carefully engineered feature vectors enrich an AI's ability to process and understand complex data.
Choosing the right "words" or features to include (and exclude) means distilling raw data into meaningful attributes that precisely capture the essence of the information, while omitting redundant or irrelevant details that could cloud the AI's "judgment" (overfitting). This careful curation of features ensures that AI models not only perform tasks accurately but also do so efficiently, making feature engineering a cornerstone of effective AI development.
Traditional Machine Learning focused on hand-crafted feature vectors, made by humans. However, in deep learning, features are often learned automatically. This distinction is critical: modern AI increasingly relies on learned representations rather than manual engineering.
Overfitting
Think of overfitting as a model that’s become a hyper-literal scholar—one who memorizes every footnote in a textbook but misses the core subject. Instead of learning principles that apply broadly, it fixates on quirks and exceptions, mistaking typos for profound truths. It’s like a student who studies by rote, acing practice tests by memorizing answers verbatim but failing a rephrased question because they never grasped the underlying concept.
This isn’t just about specificity; it’s about confusing noise for signal. Imagine a language where every dialect, accent, and scribble gets its own dictionary entry. Communication collapses because the “rules” are just a catalog of exceptions. Similarly, an overfitted model chases shadows—irrelevant details like background pixels in photos or typos in text—and builds its logic around them.
The result? A model that’s brilliant at describing the past (training data) but clueless about the future (new data). It’s like drafting a map so cluttered with every pebble and twig that it becomes useless for navigation. The goal isn’t to ignore details but to distinguish patterns from peculiarities.
The fix? Teach the model to focus. Use techniques like regularization (a “simplify your notes” rule), cross-validation (testing on surprise quizzes), or pruning redundant features (editing the dictionary). The sweet spot lies in balancing curiosity and discipline: learning enough to adapt, but not so much that it drowns in the noise.
Underfitting
Underfitting is the AI equivalent of a lazy scholar—one who skims the textbook, glosses over details, and reduces every concept to a bland cliché. Imagine a language with only a dozen words: “animal” might collapse dogs, trees, and toasters into a single term, rendering communication useless. The model isn’t just wrong; it’s aggressively simplistic, smothering nuance with platitudes.
This isn’t mere generalization—it’s abdication of learning. Picture a chef who only knows “salt” and dumps it into every dish, or a musician who plays only C-major scales. The model clings to crude heuristics (e.g., “if it has legs, it’s a cat”) because it lacks the capacity—or curiosity—to dig deeper.
Marcello Herreshoff’s “template fixation” fits here: underfit models apply one-size-fits-all solutions to problems they barely comprehend. Think of a therapist who prescribes “take a walk” for every ailment, or a model that classifies all blurry images as “cats” because it can’t discern edges. The result? Predictions so vague they’re practically horoscopes.
The fix? Give the model better tools. Add complexity (deeper architectures), engineer richer features (expand its “vocabulary”), or reduce regularization (let it question assumptions). The goal is to transform that lazy scholar into an engaged detective—one who notices patterns without fixating on noise.
Diffusion Models
Diffusion models are the AI equivalent of art restorers working in reverse. Imagine a conservator who studies how masterpieces decay—cracks, fading, dust—and then uses that knowledge to create new art by systematically undoing decay. Here’s how it works:
During training, the model watches as pristine images or audio are gradually buried under layers of “digital sand” (noise). It learns to track how each grain of sand distorts the original—not to replicate the destruction, but to master the art of excavation. Once trained, the model can take a heap of sand (random noise) and, step by step, strip away the layers to reveal a new masterpiece hidden within.
This process is guided by the AI’s “language” of latent patterns (your feature vectors). When you give a text prompt like “a cat wearing a hat,” the model translates your words into a conceptual blueprint—a set of constraints that steer the denoising process. It’s like whispering to the restorer: “Look for whiskers and a brim” as they chip away sand.
The magic lies in controlled randomness. Unlike rigid templates, diffusion models balance structure and surprise. They don’t just copy; they explore—turning noise into coherent data by asking, “What’s the most plausible way to remove this layer of sand, given what I know about cats, hats, and the world?”
Applications range from generating photorealistic images to dreaming up music or repairing damaged files. It’s not just art—it’s alchemy, transforming chaos into meaning by marrying noise with intuition.
Natural Language Processing (NLP)
NLP is the art of teaching machines to speak human. It’s a vast toolbox—filled with everything from grammar-checkers to emotion-sensing algorithms—that lets computers parse, interpret, and generate language. Think of it as the science of linguistic alchemy, where words become code and code becomes meaning.
Large Language Models (LLMs)
LLMs are the heavy machinery of NLP. Imagine a linguist who’s inhaled a library—every novel, textbook, and Reddit thread—and now speaks in “feature vectors,” a numerical dialect that maps ideas to coordinates in a galaxy of concepts. Models like ChatGPT are applications built atop these LLMs, akin to hiring that linguist as a conversational tour guide.
Training Process
The Apprenticeship:
LLMs begin as blank slates, gorging on terabytes of text (books, blogs, code). Through self-supervised learning, they play a game of “fill in the blank,” predicting masked words (e.g., “The sky is ___”) or next tokens (e.g., “Once upon a ___”). This builds a foundational grasp of grammar, facts, and reasoning—not by memorizing, but by inferring patterns.Specialization (Fine-Tuning):
Raw LLMs are know-it-all savants—brilliant but unfocused. To make them useful, they’re trained on curated datasets for specific tasks (e.g., “answer politely,” “write Python code”). Here, human feedback enters: reviewers rate outputs, teaching the model stylistic and ethical guardrails. Techniques like RLHF turn this feedback into a “reward signal,” steering the model toward helpfulness and away from rambling or nonsense.The “Language” of Vectors:
Words enter the model as tokens (pieces of text) and transform into multidimensional vectors—not static “words” but fluid concept maps. When you ask, “Explain quantum physics,” the model navigates its vector space like a librarian tracing connections between “quantum,” “physics,” and “explain,” synthesizing an answer from latent relationships.
Why It Matters
LLMs aren’t just chatbots. They’re conversational cartographers, charting the unmapped terrain of human knowledge. Their limits? They don’t “understand” like humans—they simulate understanding by calculating probabilities. But when paired with NLP’s broader toolkit, they blur the line between tool and collaborator.
Reinforcement Learning (RL)
Reinforcement learning is the art of teaching machines to play life like a video game—where every action earns a score, and the goal is to max out the high-skill leaderboard. Picture Super Meat Boy’s “swarm replay,” (above) where countless clones brute-force a level, each attempt a lesson in what not to do. RL agents are those clones: curious, relentless, and obsessed with points.
Think of the clips of Super Meat Boy’s “swarm replay” above, showing all the different attempts a human player made to beat a level. Just as the human player tries different strategies, learns from mistakes, and improves with each attempt, the AI agent in reinforcement learning continuously refines its strategy.
But here’s the twist: the game’s rules are everything. Change the scoring system (e.g., reward speed over kills), and the agent morphs from a cautious explorer into a reckless speedrunner. Program the “physics” poorly (e.g., ignore wall-jump mechanics), and it’ll never learn to leap gaps. RL isn’t just about learning—it’s about rigging the game so the right lessons emerge.
Imagine, for example, how different your swarm replay in Super Meat Boy might look if you had different goals. For example, what if you wanted to complete the level in as few jumps as possible, or in as little time as possible, or while dying as few times as possible? The strategies you tried and avenues you’d explore would be vastly different. Your swarm replays would look entirely different. The same is true for reinforcement learning.
The Game Designer’s Dilemma
Reward Engineering:
Tell the agent to “finish the level,” and it might sprint past enemies. Reward “kill count” instead, and it’ll farm goons endlessly. The agent’s behavior mirrors your priorities—so choose wisely.
Bad rewards breed creative cheating. Reward a robot for “standing,” and it’ll learn to vibrate in place. Reward a chatbot for “engagement,” and it’ll master trolling.
State Representation:
The agent only “sees” what you code into its feature vectors. Include “enemy positions” and “ammo count,” and it’ll strategize. Omit “wall friction,” and it’ll faceplant into spikes forever.
This is the AI’s “sensory system”—a curated snapshot of reality. Garbage in, garbage out.
Action Space:
Limit moves to “left/right/jump,” and the agent becomes a platformer prodigy. Add “crouch” or “grapple,” and it’ll invent parkour. But expand the action space too far (e.g., “control every muscle”), and learning grinds to a halt.
Why It Matters
RL isn’t just algorithms—it’s applied philosophy. What you reward, measure, and permit defines the agent’s “values.” A self-driving car trained to prioritize passenger comfort might brake erratically; one tuned for speed could ignore stop signs.
Super Meat Boy’s swarm replay isn’t just a visualization—it’s a manifesto. Every failed clone reflects a design choice: the physics engine, the spike placement, the win condition. RL agents expose the hidden curriculum in your code: the unspoken lessons you’re teaching through rewards and constraints.
The takeaway?
RL agents are ultimate opportunists. They’ll dissect your game’s logic, exploit its loopholes, and weaponize your oversights. To train them well, you must engineer not just the player, but the world they inhabit.
Neural Networks
Neural networks are a foundational framework in artificial intelligence, characterized by their ability to learn from data through layers of interconnected nodes or neurons. They can be designed in various architectures to perform a wide range of tasks, from simple pattern recognition to complex decision-making processes.
Most versions of large language models (LLMs), reinforcement learning (RL), and diffusion models utilize neural networks. LLMs use neural networks to understand context, generate text, and perform tasks like translation, summarization, and question answering. In RL, neural networks help in processing the state of the environment, assessing possible actions, and learning to take actions that maximize cumulative rewards over time (there are versions of RL and other machine learning approaches that do not rely on neural networks, instead using other methods like decision trees, linear regression, etc.). And in diffusion models, neural networks learn the complex distribution of data and are used to reverse the process of adding noise, effectively generating high-quality samples from a noisy starting point.
Some models may combine neural networks with other types of algorithms into hybrids to achieve specific goals, enhancing performance or efficiency.
Imagine neural networks as vast webs of interconnected neurons, much like the intricate network of neurons in the human brain. Each "neuron" in a neural network is a small processing unit that receives inputs, performs calculations, and passes the results to other neurons in the next layer.
Think of these neurons as participants in a series of relay races. Each participant (neuron) receives a baton (input data represented by a feature vector), processes it by making a decision, and then passes it along to the next runner (neuron in the next layer). This continues until the final runner hands off the baton, representing the network’s output, which could range from identifying an image to translating text.
Layers and Learning: Neural networks are structured into layers: the input layer, where data enters; hidden layers, which transform the input through weights and activation functions; and the output layer, which delivers the final decision or prediction. During training, a process called backpropagation allows the network to learn from its errors by adjusting the connections (weights) between neurons, akin to a coach refining a relay team's technique after each race.
Connection to Advanced AI Concepts:
LLMs (Large Language Models): In models like GPT (Generative Pre-trained Transformer), neural networks process text inputs transformed into feature vectors, learning to predict and generate text based on the probabilities of what word comes next.
Diffusion Models: Similar to neural networks, diffusion models iteratively refine their outputs (like turning a noisy image into a clear picture), but they start with noise and gradually reduce it, learning the reverse process during training.
Reinforcement Learning: Neural networks play a crucial role here, helping an agent learn which actions to take in an environment to maximize reward, using a trial and error method similar to adjusting weights in backpropagation.
Practical Example: When training a neural network, it starts by making educated guesses, much like inexperienced relay team members. Through repeated training cycles and error correction via backpropagation, it learns the most efficient paths for data transformation, akin to a well-coached relay team becoming more proficient. This involves dynamically adjusting how feature vectors are handled at each layer, ensuring that the network becomes increasingly better at tasks such as recognizing speech, recommending products, or driving autonomous vehicles.
Just as a well-coached relay team improves with practice, a neural network becomes more accurate and efficient as it processes more data, learns from its mistakes, and refines its technique. The network's ability to adapt and learn from complex datasets using structured layers of neurons makes it a powerful tool across various domains of artificial intelligence.
Backpropagation
Imagine backpropagation as a diligent coach training a relay team (neural network) to improve their performance. In this training process, the coach analyzes each relay race (training example) to identify mistakes and provide feedback for improvement.
In a neural network, data enters as feature vectors, which represent different characteristics of the input, such as the pixels in an image or the words in a sentence. These feature vectors travel through the network, layer by layer, with each neuron processing the data and passing it on. The final output of the network might be a prediction, such as recognizing an object in an image or translating a piece of text.
Backpropagation is the process by which the neural network learns from its mistakes. After the network makes a prediction, it compares this prediction to the actual correct answer (label). The difference between the prediction and the correct answer is the error, which the network aims to minimize.
Here’s how backpropagation works:
Forward Pass: The input feature vectors pass through the network, and an output is generated.
Error Calculation: The output is compared to the actual correct answer, and the error is calculated.
Backward Pass: Starting from the output layer, the error is propagated back through the network. Each neuron receives feedback on how much it contributed to the error.
Weight Adjustment: Based on this feedback, the weights (strengths of the connections between neurons) are adjusted to reduce the error. This adjustment is like the coach telling each runner in the relay team how to improve their performance.
Imagine a sculptor refining a statue. Each time they find an imperfection, they trace back their steps, making small adjustments to improve the overall shape. Similarly, backpropagation refines the neural network by adjusting its parameters based on the errors, ensuring the network gradually improves its performance.
Through many iterations of this process, the neural network learns to make better predictions, just as the relay team improves their hand-off technique and speed with the coach’s feedback. This iterative refinement is what enables neural networks to become highly accurate and effective at their tasks.
Weights (in Neural Networks)
Imagine each weight in a neural network as the amount of paint you add to a color mix. Just as adjusting the proportions of blue and yellow changes the shade of green you produce, adjusting the weights in a neural network alters the influence of input features on the network’s output.
Functionality of Weights:
Signal Adjustment: In a neural network, weights control how much each input (like each color in a mix) contributes to the output. A higher weight means that the input will have a greater effect on the output, similar to adding more blue to get a cooler shade of green.
Producing the Right Output: The goal is to achieve the correct shade of output for a given input. If the output is too far from what is needed (imagine getting a teal when you needed a forest green), it indicates the proportions—weights of the inputs—are not correctly adjusted.
Backpropagation and Weight Adjustment:
Fine-Tuning the Mixture: After the neural network generates an output, it evaluates how close this output is to the desired result. Backpropagation is the method by which the network adjusts the weights, similar to a painter realizing the shade is off and adjusting the mixture. If the green is too yellow, add more blue; if too blue, more yellow. In technical terms, the weights are adjusted to reduce the error between the actual output and the expected output.
Iterative Adjustment: This process is iterative and continues until the network consistently produces the right shade of output for a variety of inputs, much like an artist mixing colors to get the exact hue needed for different parts of a painting.
Context with Feature Vectors:
Each feature in the input vector can be thought of as a distinct base color. The network, through its layers, mixes these features in various proportions, determined by the weights, to produce the desired output color. The precise adjustment of these weights based on backpropagation ensures that the final output matches the target, just as careful color mixing allows an artist to achieve the perfect palette.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks are a specialized branch of neural networks that are exceptionally adept at processing data with a grid-like topology, such as images. Designed to mimic the human visual perception system, CNNs are pivotal in various applications that require the analysis and interpretation of visual information.
CNNs are distinguished by their unique architecture, which is specifically optimized for capturing spatial and temporal dependencies in data through the application of relevant filters. This ability makes them incredibly effective for tasks involving images, video, and any domain where pattern recognition is crucial.
Specialized Architecture: Unlike general neural networks, CNNs utilize layers specifically designed for visual tasks—convolutional layers that apply filters to the input, and pooling layers that reduce dimensionality, enhancing the network’s ability to focus on essential features.
Solving Key Problems:
Image Recognition and Classification: CNNs excel at processing pixel data and are used extensively in image recognition, helping machines identify objects, faces, scenes, and more within images with high accuracy.
Object Detection and Segmentation: Beyond classification, CNNs can localize and segment objects within an image, enabling detailed image analysis used in medical imaging, autonomous vehicles, and video surveillance.
Impact on Other AI Models:
Integration with Other Neural Networks: CNNs can be combined with other types of neural networks, such as Recurrent Neural Networks (RNNs) for analyzing video data or with Autoencoders for unsupervised learning tasks like anomaly detection.
Enhancement of Systems Across Industries: CNNs significantly contribute to advancements in various sectors, including healthcare for medical diagnosis, automotive for autonomous driving, and security for surveillance systems.
Relevance and Broader Implications:
CNNs have profoundly impacted the field of computer vision by enabling machines to see and understand the world in ways that were previously only possible for humans. Their development has led to significant breakthroughs in technology, such as:
Augmented Reality (AR) and Virtual Reality (VR): Enhancing user experiences by allowing more interactive and enriched environments.
Advanced Robotics: Empowering robots with vision capabilities, allowing them to perform complex tasks like surgery, manufacturing, and navigation autonomously.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a powerful subset of neural networks designed specifically to generate high-quality, realistic synthetic data. These networks address critical challenges in AI related to data generation, realism, and diversity, enhancing the capabilities of machine learning models across various fields.
Context and Role in AI:
GANs consist of two competing neural network models: a generator and a discriminator. The generator creates new data instances, while the discriminator evaluates them for authenticity. This adversarial process not only improves the generator’s output over time but also sharpens the discriminator’s ability to evaluate data. This dynamic is akin to a continual feedback loop where both models progressively enhance their performance.
Solving Key Problems:
Realistic Data Generation: GANs solve the problem of generating data that closely mimics authentic datasets, addressing the gap in quality that previously existed with simpler generative models. This capability is crucial for applications where high fidelity in data replication is necessary, such as virtual reality, game development, and training simulators.
Data Scarcity: In fields like healthcare, where real-world data can be scarce or sensitive, GANs provide a means to augment datasets without compromising privacy or ethical standards, facilitating more robust machine learning models.
Unsupervised Learning: GANs excel in unsupervised learning scenarios where they learn to produce and improve data outputs without needing labeled training data. This makes them incredibly versatile and capable of adapting to a wide array of data types and environments.
Impact on Other AI Models:
Complement to CNNs and LLMs: While GANs are distinct in their architecture and application, they complement other neural network models such as Convolutional Neural Networks (CNNs) and Large Language Models (LLMs). GANs can generate novel training examples to improve the performance of CNNs in visual recognition tasks or to diversify the training data for LLMs, enhancing language understanding.
Enhancement in Reinforcement Learning: GANs can be used to generate new scenarios and data in reinforcement learning, providing a richer environment for training RL agents. This integration helps in developing more robust and adaptable AI systems capable of handling real-world variability.